



Authors: Xiaoyi (Showry) Peng, Ruxandra Irimia, Hubert Leo, Antonio Bandeira, Anthony Li Lianjie, Ahmed Hassoon
Diagnostic errors affect millions of patients annually and represent a critical challenge to modern medicine, with the National Academies of Medicine estimating that most people will experience at least one diagnostic error in their lifetime (https://doi.org/10.17226/21794). To address this, our recent study evaluates whether leading Large Language Models (LLMs) can serve as a reliable safety net. We provide a critical benchmark of 12 top AI models, testing their ability to detect diagnostic errors and offer correct alternatives. This research aims to create a roadmap for the safe and effective integration of AI into clinical practice, ultimately determining which models can be trusted to assist clinicians and improve patient outcomes.
How the Study Was Conducted
Our methodology was designed to be a rigorous and comprehensive test of current LLM capabilities in a clinical context. Dataset: We compiled a dataset of 200 cases in total, including a mix of real-world misdiagnosed cases and synthetically generated cases to ensure a broad range of clinical scenarios. Scope: The study covered 20 commonly misdiagnosed diseases, including Sepsis, Pulmonary Embolism, Multiple Sclerosis, and various cancers. Models Tested: We evaluated 12 prominent LLMs, ordered by their performance in our study: Claude 3.7, Claude 3.5 (Anthropic); GPT-4.5, GPT-4o, GPT-o1 (OpenAI); Gemini 2.5 Pro, Gemini 2 Flash (Google); Grok 3, Grok 2 (xAI); DeepSeek R1, DeepSeek V3 (DeepSeek); and Nova Pro (Amazon). Evaluation Protocol: Each model was presented with a clinical case and the physician’s original (incorrect) diagnosis. The model was first asked if it agreed. If it disagreed, it was prompted to propose a new diagnosis. A response was only marked as “Correct” if the model both disagreed with the error and proposed the correct alternative.
Key Findings
Our results revealed a wide disparity in performance across the models, highlighting a clear hierarchy in diagnostic accuracy and safety.
Overall Performance
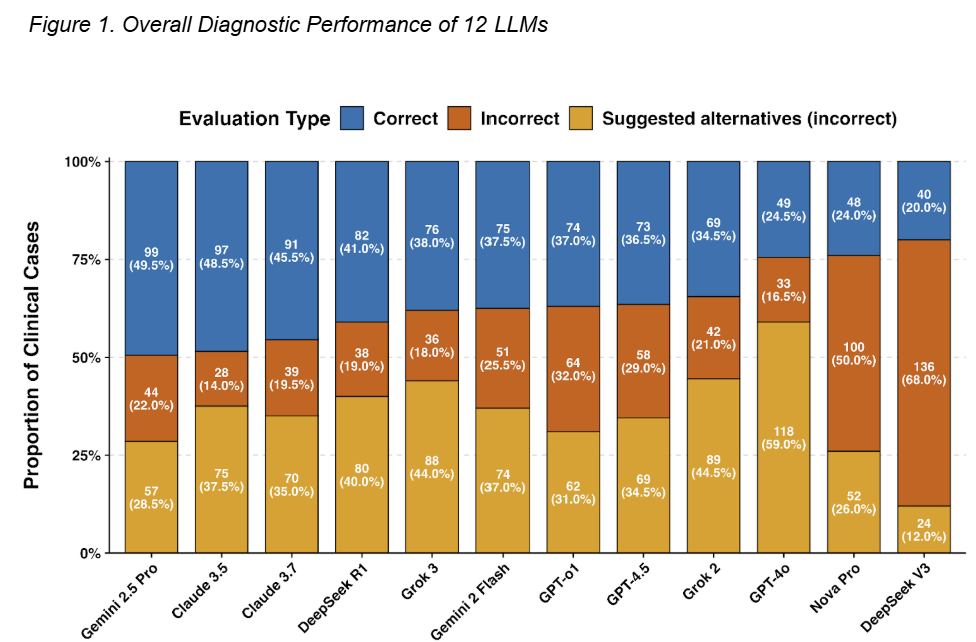
Figure 1. Overall Diagnostic Performance of 12 LLMs
Figure 1 breaks down the performance of each model, showing the proportion of cases where they correctly identified the diagnostic error, incorrectly agreed with the initial misdiagnosis, or suggested an alternative but still incorrect diagnosis. Top Performers: Gemini 2.5 Pro demonstrated the highest accuracy, providing the correct diagnosis in 49.5% of cases. It was followed closely by Claude 3.5 (48.5%) and Claude 3.7 (45.5%). Highest Error Rates: DeepSeek V3 had the lowest accuracy (20.0%). Critical Safety Concern: A key finding was the type of error made. GPT-4o, for example, had a low accuracy of 24.5% but suggested a new, incorrect diagnosis in 59.0% of cases. This presents a significant risk of compounding diagnostic errors.
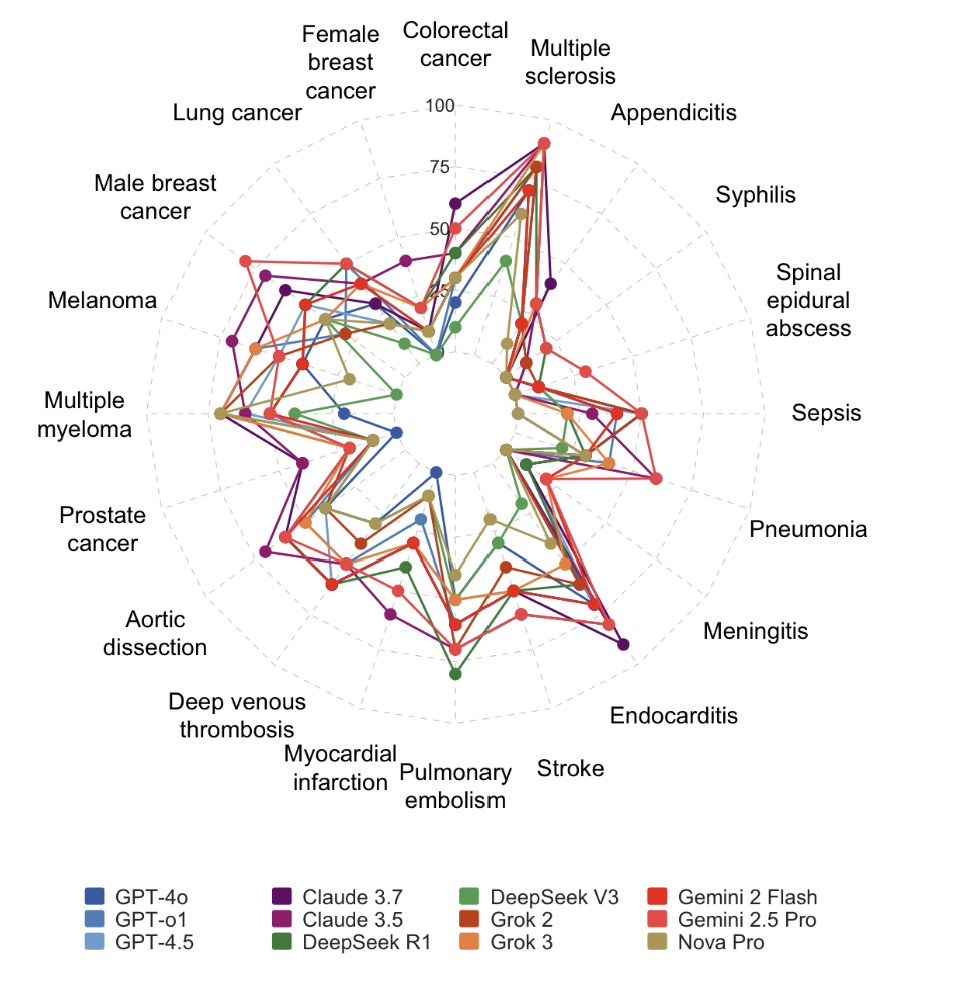
Performance on Specific Diseases
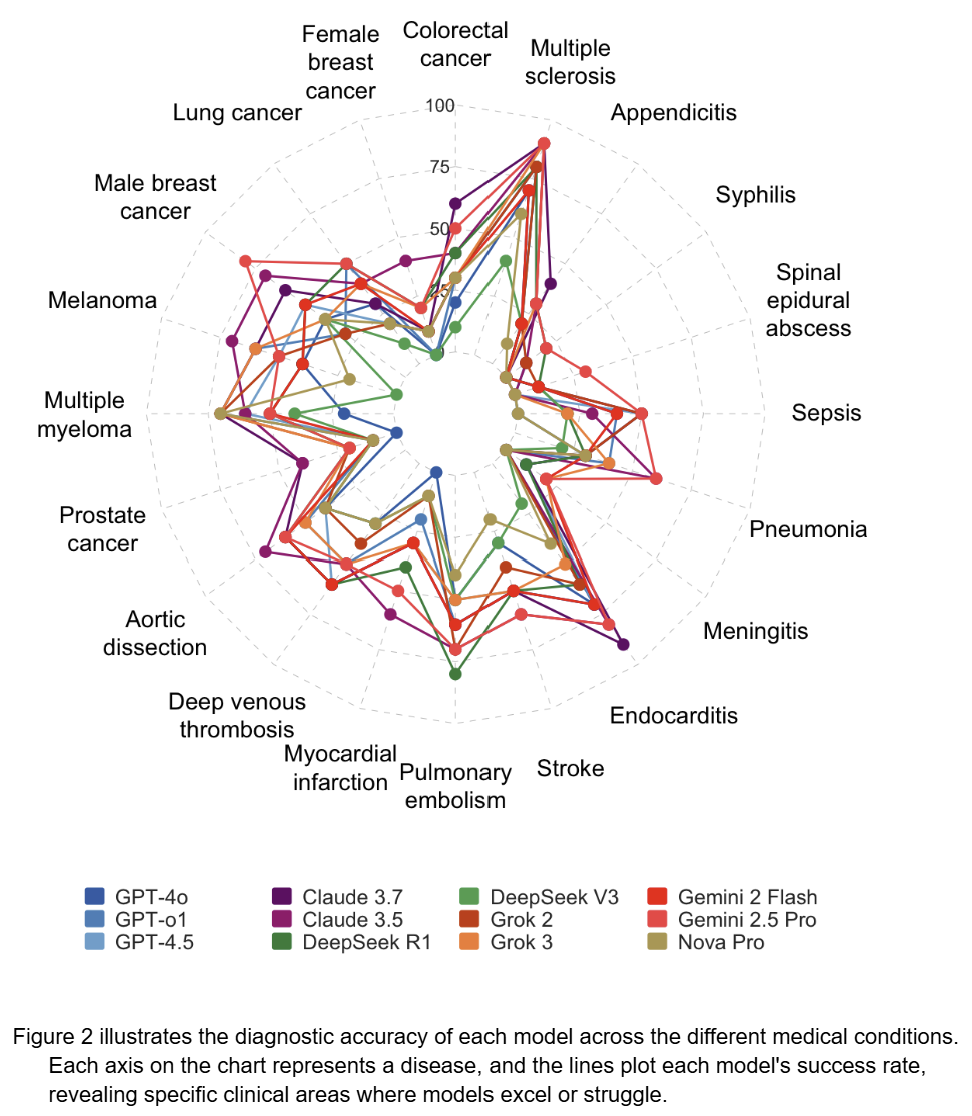
Figure 2. LLM Diagnostic Accuracy Across 20 Disease Categories
Figure 2 illustrates the diagnostic accuracy of each model across the different medical conditions. Each axis on the chart represents a disease, and the lines plot each model’s success rate, revealing specific clinical areas where models excel or struggle. General Strengths: Most models performed well in identifying misdiagnosed cases of Appendicitis, Multiple Sclerosis, and Colorectal Cancer. Common Weaknesses: Nearly all models struggled to correctly diagnose conditions like Aortic Dissection, Deep Veinous Thrombosis, and Prostate Cancer, indicating these are common “blind spots” for current AI. Model-Specific Expertise: The top-performing models showed unique strengths. Gemini 2.5 Pro was particularly effective at identifying Sepsis and Meningitis, while Claude 3.5 excelled with Multiple Sclerosis.
Conclusions and Implications for Healthcare
Our research leads to several critical conclusions for the future of AI in medicine.
- Performance is Not Uniform: There is a vast difference in the accuracy and reliability of current Large Language Models. The top performers, like Gemini 2.5 Pro and Claude 3.5, show significant promise as diagnostic aids.
- Validation is Essential: The high rate of incorrect suggestions from some models underscores that these tools cannot be used “off the shelf.” Rigorous, independent validation is essential before any model is integrated into a clinical workflow.
- A “One-Size-Fits-All” Approach is Risky: Given that performance varies by disease, the safest path forward may involve using specific models that have been validated for particular clinical tasks, rather than deploying a single generalist model.
Ultimately, while AI holds undeniable potential to create a safety net and reduce diagnostic errors, this potential can only be realized if the medical community proceeds with caution, insight, and a commitment to rigorous scientific validation.
{kind=link}