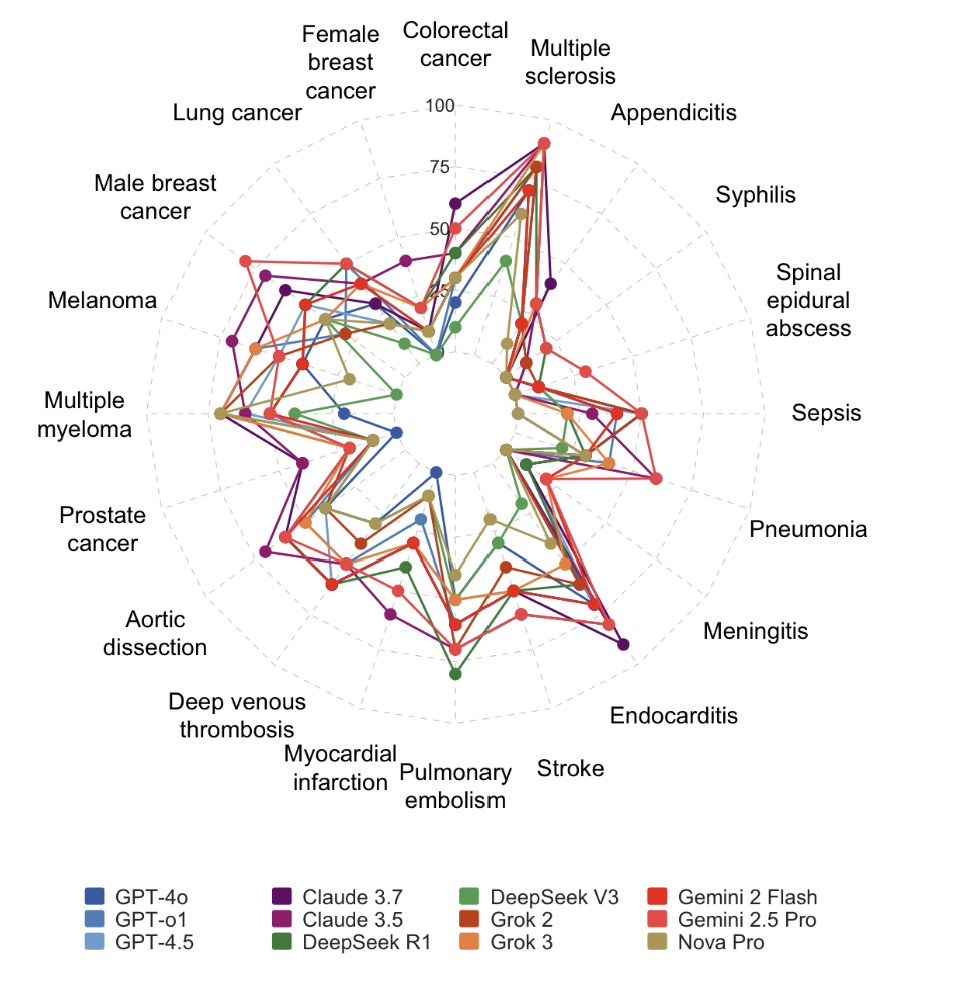




Can AI Catch What Clinicians Miss? A Comparative Study of Diagnostic Accuracy
A critical benchmark study evaluating whether leading Large Language Models (LLMs) can reliably detect diagnostic errors and improve clinical outcomes.
A critical benchmark study evaluating whether leading Large Language Models (LLMs) can reliably detect diagnostic errors and improve clinical outcomes.
Building a great model is only half the battle. MLOps (Machine Learning Operations) is the discipline of deploying, monitoring, and maintaining models in production reliably and efficiently.
A simple train/test split is not always enough. Learn how K-Fold Cross-Validation provides a much more robust estimate of your model's performance on unseen data.
An introduction to Support Vector Machines (SVMs), a powerful and versatile supervised learning algorithm capable of performing linear or non-linear classification, regression, and outlier detection.
A fundamental concept in machine learning, the Bias-Variance Tradeoff explains the delicate balance between a model that is too simple and one that is too complex. Understanding it is key to diagnosing model performance.
Machine learning models have many knobs and dials called hyperparameters. Learn how to tune them effectively using techniques like Grid Search and Random Search to unlock your model's true potential.
Learn about one of the most common pitfalls in machine learning—overfitting—and explore powerful techniques like L1 (Lasso) and L2 (Ridge) regularization to build more generalizable models.
Building a model is one thing, but how do you know if it's any good? We'll explore essential evaluation metrics for classification and regression to help you measure and compare your models' performance.
An overview of Gradient Boosting, a powerful ensemble technique, and its most famous implementation, XGBoost, which is renowned for its performance and speed, especially on tabular data.
A guide to understanding Decision Trees and their powerful successor, Random Forests. Learn how these intuitive, flowchart-like models make decisions and why they are so popular in machine learning.
A look into unsupervised learning, the branch of machine learning that finds hidden patterns and structures in unlabeled data, focusing on clustering and dimensionality reduction.
Explore the fundamentals of Reinforcement Learning (RL), the area of machine learning where agents learn to make optimal decisions by interacting with an environment and receiving rewards.
Discover how BERT (Bidirectional Encoder Representations from Transformers) revolutionized NLP by learning deep contextual relationships, and how transfer learning allows us to leverage its power for custom tasks.
An exploration of the Transformer architecture and its core component, the self-attention mechanism, which has become the foundation for modern large language models like GPT and BERT.
Dive into Long Short-Term Memory (LSTM) networks, a special kind of RNN that can learn long-term dependencies, revolutionizing natural language processing and time-series analysis.
An introduction to Recurrent Neural Networks (RNNs), the models that give machines a sense of memory, making them ideal for tasks like translation, speech recognition, and more.
A deep dive into Convolutional Neural Networks (CNNs), the powerhouse behind modern computer vision. Learn how they 'see' and classify images with incredible accuracy.
A beginner-friendly guide to understanding backpropagation, the fundamental algorithm that powers deep learning. We'll break down the concepts and provide a practical code example.
Explore the fascinating world of Generative Adversarial Networks (GANs), where two neural networks compete to create stunningly realistic images, music, and more.
Find out how to set up a successful blog or how to make yours even better!
A critical benchmark study evaluating whether leading Large Language Models (LLMs) can reliably detect diagnostic errors and improve clinical outcomes.
Building a great model is only half the battle. MLOps (Machine Learning Operations) is the discipline of deploying, monitoring, and maintaining models in production reliably and efficiently.
A simple train/test split is not always enough. Learn how K-Fold Cross-Validation provides a much more robust estimate of your model's performance on unseen data.
An introduction to Support Vector Machines (SVMs), a powerful and versatile supervised learning algorithm capable of performing linear or non-linear classification, regression, and outlier detection.
A fundamental concept in machine learning, the Bias-Variance Tradeoff explains the delicate balance between a model that is too simple and one that is too complex. Understanding it is key to diagnosing model performance.
Machine learning models have many knobs and dials called hyperparameters. Learn how to tune them effectively using techniques like Grid Search and Random Search to unlock your model's true potential.














